Server
Introduction
In addition to be usable as a library, TimeSide has furthermore been built into a Django server with a relational PostgreSQL database in order to store music tracks and processing results. Data structure and relations are defined in the models to ensure easy data serialization. The backend is built with Django REST Framework to provide a documented RESTful API. It guarantees interoperability by allowing other servers or multiple frontends to interact with the TimeSide instance. Any application consuming the API is then able to:
upload audio track or retrieve them from remote providers
stream original or transcoded sources
run on-demand analysis with customized parameters
deliver and share several types of results: transcoded audio, numerical or graphical outputs of analysis,
collect tags and indices on tracks to build annotated audio corpora for further machine learning purpose.
Architecture
The web service are provided by a Docker composition. The following diagram shows how containers interact each other where each container is represented by a specific color. The Backend is able to delegate all the processing asynchronously to the Worker through the Broker. The Backend and the Worker share the same Core library and related plugins.

Models and Serializers
The models of the backend are defined as usual Django models. Here is a non-exhaustive list of the main models:
Item: an audio resource with a source file or a URLSelection: a list of ItemsProcessor: a processor provided by the core module and all related pluginsPreset: a Processor with some parameters in the JSON formatExperience: a list of PresetsTask: a list of Selection linked to an Experience to runResult: a result of the processed Experience for an itemProvider: a web service providing audio content (e.g. Youtube or Deezer)
See this diagram and the full API documentation to learn all the properties and methods of these models.
This modelization allows to define a specific precessing Experience that can be re-processed on any new Selection which is especially convenient for analysis on growing datasets. All model instances and related data are accesible through a REST API with authentication. This ensures that a client can consume TimeSide as a dedicated and autonomous web service.
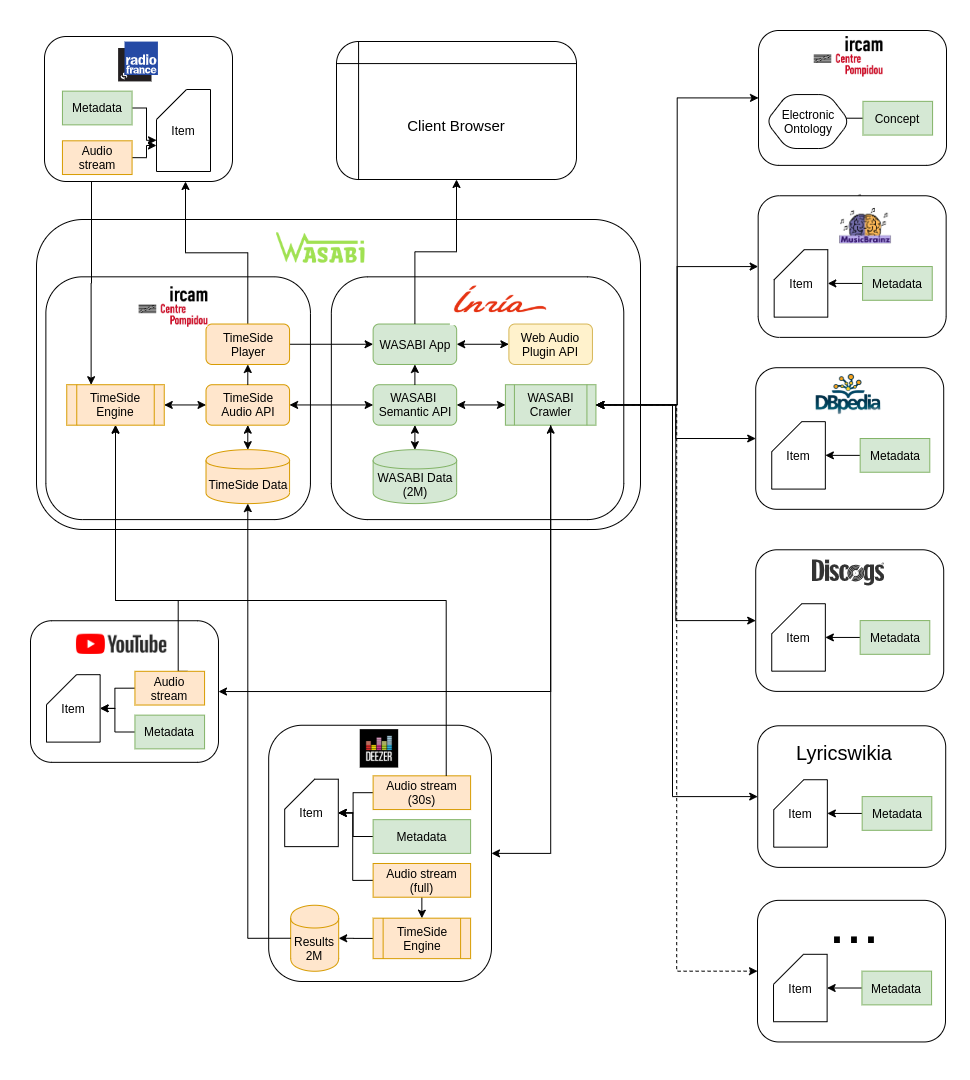
All the resources stored in the database are indexed with UUIDs so that any data coming from a timeside instance can be loaded any other without losing links and history. As an example, the following diagram shows how, during the WASABI project, some public data have been processed onto the Deezer infrastructure and then imported back into the main TimeSide database without loosing precious data linkage.
Results and Formats
When an Experience has been processed on a Item, all the result data are stored on the filesystem as HDF5 files which are indexed in the database through the Result django model. As provided by the core module and explained in the Data management section, the data can be serialized to various formats like JSON, YAML or XML. The HDF5 file contains all the preset parameters and data structure so that, if a process is requested for the same Item, same Processor version, the data will be automatically retrieve from the database and eventualluy re-processed in another child processor or serializer.
From the server shell, a result can be retrieved like this:
docker compose run app python manage.py shell
>>> from timeside.server.models import Result
>>> from timeside.core.analyzer import AnalyzerResult
>>> result = Result(uuid="c0a6e49e-b315-467a-8578-d42f796a197a")
>>> data = AnalyzerResult().from_hdf5(hdf5_result)
>>> print(data.as_dict())
To postprocess the data, see User Interfaces.
Note
When the data is requested through the API, it is automatically serialized into JSON for vectors, PNG for images and FLAC for audio.
Developing a new server feature
First, setup the development environment at the root of the project:
echo "COMPOSE_FILE=docker compose.yml:env/debug.yml" > .env
docker compose up
Then any change on the server part will be dynamically updated in the container thanks to the django debug server.
To add data and test, just browse:
http://localhost:8000/admin/
or
http://localhost:8000/api
REST API
To develop an external client on top of the server API, a full documentation of the rules and object properties is available online.
Javascript SDK
In order to build applications on top of the REST API, a SDK is available for the Typescript and JavaScript languages using the OpenAPI standard. It has been created from the routes of the OpenAPI schema automatically exported from the backend thanks to the OpenAPI Generator. The SDK proposes some examples for clients to reach the server and request some processing.
As an example, an original multi-dimensional HTML5 player is described in the User Interfaces section.
Providers
The Provider class allow to systematize the downloading or the streaming methods of audio content coming from specific platforms thanks to their metadata link URLs or IDs. This is particulary convinient to analyze large playlists and public datasets from YouTube and Deezer for example.
The Provider objects are automatically created in the database at the server startup regarding the Provider plugins available in the Core library.
To add a YouTube video, just fill the external_url of the new Item. The server will automatically retrieve the metadata, the audio stream of the video (generally taken in the Opus format) and then produce the first waveform.
We provide some scripts to automatically push a list of YouTube videos into the database from a JSON files containing a list of URLs as well as Deezer preview track lists.
Backup
A PostgreSQL server is used as the default database in its own container. The database can be backup with the common dump and restore postgres commmands. Some shortcuts will soon be provided.
Dump and load
Every resources stored into the database has an UUID as its primary key. This ensures that a clean export of all the data can be import in another TimeSide instance. It is particulary useful when you need to compute a specific Experience on top of a private datasets somewhere and then import all the Results in another private or public instance, without the original private data.
To dump all data from the database as a JSON file, just do:
docker compose run app python manage.py dumpdata timeside.server timeside.core -o /srv/backup/data.json
Then copy it in the var/backup directory of another instance and import it:
docker compose run app python manage.py loaddata -o /srv/backup/data.json /srv/backup/data.json
Of course, you will also need copy all the binary data stored in the var/media directory to the same server, using rsync for example:
rsync -a var/media/ foo.bar.com:/srv/TimeSide/var/media/